転職します
10/15で10年間勤めた岡山の会社を退職し、10/18から東京のスタートアップ企業でのフルリモート勤務が始まります。
なぜ転職したのか
現在45歳ですが、10年後、20年後も働き続ける必要があると考えています。その時どんな仕事をやっているのかを想像すると、現在のマネージメント業だけでは少し厳しいかなと感じるようになってきました。そのため、もう少しスピード感を持って技術寄りな仕事がしてみたいと思い転職することにしました。
今までは何をやってきたのか
Railsプロジェクトのプログラマーから始まり、CIやインフラの構築を行ってきました。直近の2〜3年はマネージャーとしてチームビルディングを意識して動いてきました。
これから何をやるのか
Railsのバックエンドエンジニアとして活躍する予定です。将来的には社内の技術的な強みと辛みを把握した上で、マネージメント業ができたら良いなと考えています。
気をつけること
リアルで一緒に仕事をした事がないメンバーとの業務になるので、まずは信用を勝ち取ることが大切だと思っています。
- 約束は守る
- メンションには素早く反応する
- 既存のドキュメントはちゃんと読む
当面は↑に気をつけながら毎日の業務を行ってみようと考えています。
そーだいさんに教えてもらったこと
自信喪失でぴえんモードになってるので「そんなことないよ、そーだいさんすごいよ」ってチヤホヤしてくれる会が必要。
— そーだい@初代ALF (@soudai1025) 2021年5月26日
そーだいさんからはとても多くの言葉をもらっていて、とてもTwitterには書ききれないためブログにまとめてみました。僕にもそーだいさんの元気にある言葉を教えてください!!
— そーだい@初代ALF (@soudai1025) 2021年5月26日
前置き
私にとってのそーだいさんは岡山や福山を中心としたIT系勉強会の仲間という認識だったのですが、いつの間にやらCTOになったり雑誌や書籍の執筆活動したり会社を立ち上げたりすごい人になっちゃってました。
実は2019年5月から2020年7月まで毎月1on1をしてもらってました。当時、マネージャーになりたての私の悩みに寄り添い、大変多くのアドバイスを貰いました。 「アドバイス」というのは面白いもので、聞いた当初と今とでは話の深みが全く変わってくるものなんですね。経験を積むことによって「あのとき、本当に伝えたかったのはこういうことか」と認識することが多くなってきます。今回はいくつかのエピソードを振り返ってみます。
コミュニティ
そーだいさんとコミュニティの話をすると「恩送り」という言葉をよく聞きます。これはコミュニティによって育ててくれた先輩たちに直接お返しをすることはできないけど、後輩たちに恩を送ることが先輩たちへのなによりの恩返しだよという話です。これはIT系勉強会に限らず一般的な会社にも言えるのではないでしょうか?私は10年前に今の会社に転職してきましたが、先輩たちからやってもらって嬉しかったことは会社は違えど後輩たちにやってあげたいと思ってます。そういう組織の枠を超えて、後世に叡智を語り継いでいくのは人間の営みそのものではないかと思います。
管理職
2019年頃、私はいわゆるプレイヤーからマネージャになりました。今までRubyやインフラ面でパフォーマンスを出していたつもりですが、すぐに気持ちを切り替えれるほどの覚悟や自覚はありませんでした。当時の私は「1on1」や「スクラム開発」などマネージャとしてやるべきワードに囚われており本質が見えてませんでした。そんな私にそーだいさんは「1on1自体がやりたいわけじゃないでしょ?チームメンバーと何を話したいの?」という疑問を投げかけてきました。「エンジニアに寄り添いたい」などとそれっぽい事を言う私に「寄り添うってなんだろう?」と返されました。そこで私は深く考えることになります。「エンジニアが好きな技術だけ取り組んでいればよいというものではなく、組織として成果を出していく必要がある。そのためには個人がやりたいことと会社がやってほしいことのバランスが取れていることが大切。そのすり合わせを行うのが1on1だ。」と今なら自身を持って答えることができます。
また、そーだいさんはマネージャは信頼を勝ち取るものと教えてくれました。そのためには「きっちり説明することが大切。やると宣言したことは必ず行い、できなかったらちゃんと理由を説明する。それが責任だ」という話でした。現在管理職の「責任」とはなんだろう?って考えることがよくあるのですが一番は説明責任だと思っています。特に開発の現場では障害発生時の説明や分析が大変だけどとても重要だと感じています。
こんなこともありました。「自分がやっているマネジメントの方針が正しいかどうかわからない」という疑問をぶつけた時があるのですが、チームメンバーについてアンケートを取るように言われました。私は言われたとおりアンケートを依頼したのですが返ってきたのは当たり障りのない返事ばかり。そりゃそうですよね。私は評価者なのでメンバーは悪いことは書きません。そーだいさんもこうなることは予想はついていたようで「マネージャーは自分で自分を褒めてあげる必要がある。プレイヤーよりやることが明確になっていないのがマネージャ。だからこそ給与が高いんだよ。」という話でした。 自分で自分を褒めるためには具体的やったことを明確にし、結果を記録していく必要があります。チームメンバーの目標設定や成果の記録はとても重要な私の仕事となりました。
会話
1on1でSQLの質問に対して、いくつものURLが瞬時の間に提示されたことがあります。SQLだけではなく発表資料やブログ、Twitterのリンクが瞬時にでてきます。彼の頭の中にはどういうINDEXが構築されているのでしょうか。
情報量だけではなくこちらの質問に対して「まず3つあります」と話したい内容を数で返してくることが多いです。面白いのは「3つ」と宣言した場合は多くの場合話し出すときまでは2つまでしか考えておらず、3つめは話の途中で考え出している点です。前世は噺家(はなしか)か何かだったのでしょうか。
このレスポンスの速さ・頭のキレには会話をするたびに驚かされます。
そーだいさんだめなところ
酔っ払うと正論で殴ることとがあります。相手は翌週までダメージを引きずるので程々にしておいてほしいです。まぁ年令を重ねると教習所にでも行かない限り怒られることは少なくなってきますので、ときには怒られる機会も大切かな。コロナが落ち着いて一緒に飲める日を楽しみにしています。
2020年振り返り
あけましておめでとうございます。 人生40年以上生きていると、新年を迎えても「12月の次は1月ですね」ぐらいの気持ちしか無いのですが、お正月休みを使って去年の振り返りを書いてみようと思います。
前半
新規ソフトウェア開発のPLをやっていました。今まで担当していたシングルテナントアプリケーションとは違い、マルチテナントということで色々考えることが多かったです。その分、AWSのソリューションをガッツリ使った仕組みにできて満足しています。この仕組の詳細についてはryosmsの発表内容を御覧ください。個人的にはS3にCSVファイルをアップロードすることでJasperReportを使って帳票が出力される仕組みが萌えポイントです。
この開発では私にとって初めてスクラムを実践してみました。開発初期の頃は正直なところスクラム開発をやりたくて、スクラム開発していた感がありました。今にして思えば通常のスクラム開発ではどうなのかという点にこだわりすぎていた点が反省点かなと思っています。
また初期の頃から設計者が一人で設計を行っていたのですが、設計時間が見積もりに含まれておらず予定が立てづらいかつ、開発者が「タスク」でしか物事を考えられなくなっていました。 色々相談に乗ってもらっている id:Soudai さんの提案で途中からモブ設計を実施するようにしました。3名の開発者の認識が一致するまで話し合い&設計を行うので時間はかかりますが、チケットをクローズするためには何が必要か、という観点でスプリントレビュー内で色々話ができるようになったのは良い点でした。その結果、徐々にチーム内での意見も活発になってきたのでやってよかったです。
このソフトウェアは8月末で予定通りVer.1がリリースできました。チームメンバーに感謝です!
後半
前半で得たスクラム開発のノウハウを10年近く続くプロジェクトに適用しようと四苦八苦していました。いや現在進行系で苦労してます。 この古株プロジェクトは入社より私がずっと携わっていたのですが、前半別プロジェクトの担当をしていたせいで充分目が行き届かず、チームメンバーが個人事業主化している状態でした。日々のタスクをこなすのが精一杯で、プロダクトに向き合う上で大切な「緊急度低・重要度高」のタスクが先送りされている状況でした。
チームについて考えるイベントを9月に開催
壮大さんの講義では「自立を勝ち取る」というテーマで話をしていただいたのがとても良かったです。「自律」ではなく「自立」というのがミソでセルフマネージメントをしっかりしましょうという事ではなく、チームや組織を変えて「自立」していこうという内容でした。これからのチームの方向性を決める意味では、この講義のおかげでチームメンバーの意識が変わったかなと感じています。
チーム・ジャーニーを参考にした
この頃読んだチームジャーニーには大きな影響を受けていて、チーム作りの参考にさせてもらいました。
- ジャーニー型の開発
お互いにチームメンバーのことも分かっていないうちからアジャイル開発はムリ!ということでまずはお互いを知り、自分たちができるところから始めていきました。次のような階段を設定し、達成感を感じながらチームメンバーには進んでもらうことにしました。
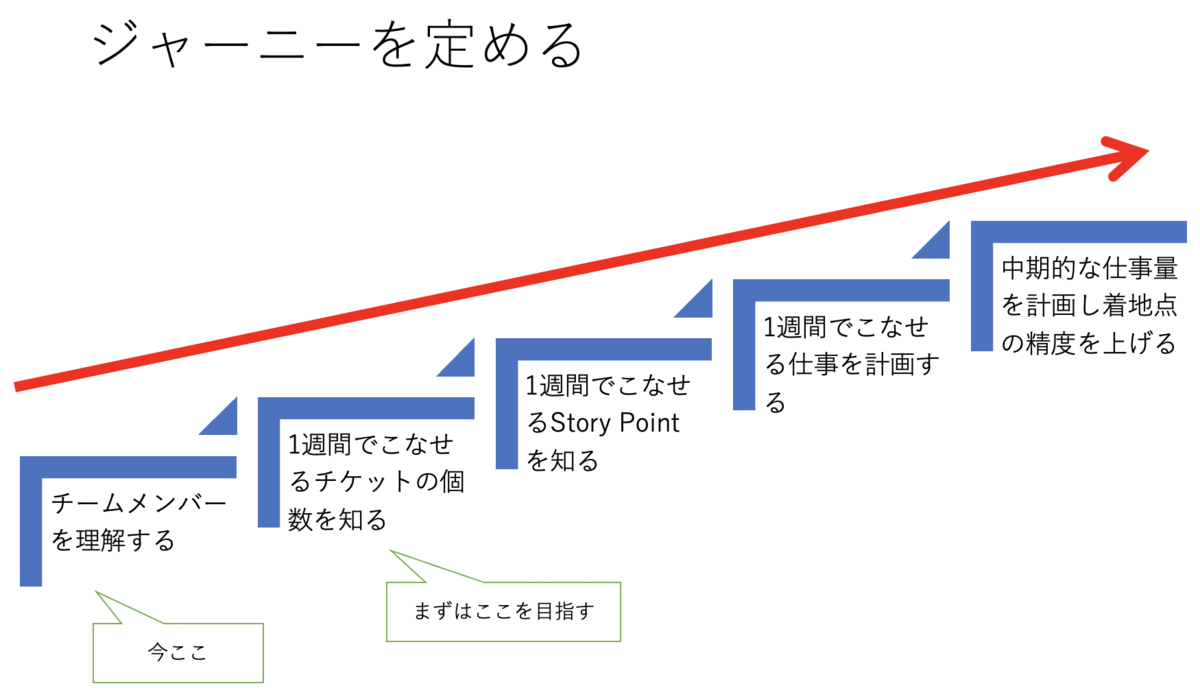
秋ぐらいからゆっくりですがチームメンバーの意識が良い方向に向かっています。プロジェクトとして次の大きな成果を上げることができました。
- レスポンシブ対応
- データ構造の変更を伴う、重い処理の高速化
- AmazonLinux2対応
- シングルテナントアプリケーションなのでお客さんごとにサーバーが沢山あったので大変だった!予定調整してくれた営業・SE部隊にも感謝
- テスターチームの組織化
- 突発対応と通常対応の持ち時間を設定
- 前半にやっていた新規開発とは異なり、こっちは日常から障害対応や問い合わせ対応、インフラの調整など開発以外の業務が多岐にわたります。担当者ごとに自分の1日の時間の何割を「突発対応」として使うか決めてもらい、それ以外の時間でスプリント計画を立てるようにしました。
これから
2つあります。
イベントから数ヶ月経過したのでそろそろ向き直りの時期かなと思っています。もう一度イベントを開きたいですね。
もう一つはフルリモートに対応した組織づくり。新型コロナウィルスの影響はあと数年は続くはずです。終息後もリモートを中心とした仕事のやり方は続いていくでしょう。そのためにもまずは自身がフルリモートに近い形態で勤務して、問題点を探し出し組織を改善していかないとなと思っています。
まずは2世帯住宅の本家(今は離れに住んでる)を改装し、仕事部屋兼、将来の子供部屋をDIYで作ります!
夏の終りISUCON10の予選に散った
ISUCON10とは
ISUCONとは「いい感じにスピードアップコンテスト」という腰から砕けていきそうなタイトルを略した、LINE主催のWebアプリケーションスピードアップコンテストのことです。どうやら今年は10回目ということで、弊社のエースエンジニア id:patorash と参加してみました。
事前準備と予備知識
予選数週間前に id:patorash と一緒に過去問にチャレンジしてみました。どうやら ISUCON4の環境が作りやすそうなのでそれで練習してみることに。NginxとSinatra, SinatraとDBをTCP接続からsocket接続に変えたり、静的ファイルはNginxで返すようにしたり、なるほど仕事でやってるようなことをやればいいのね。最後に速度低下を引き起こして申し訳ありません、改善案はコレコレですという障害報告書をWordで書かなくてもいいのね。ということを考えながらその日は終了。
ぶっちゃけ初参加だし素の状態で腕試しを!という気持ちで本番に望みました。
本番
運営側の事情で2時間押しの12時過ぎにスタート。セブンイレブンのカレーライスで腹が膨れて眠気を誘います。 役割分担は当初の予定通り私がインフラのチューニング、 id:patorash がDBのチューニングという感じで進めました。
まぁ詳しいことは id:patorash のブログを見てくだされ。
結果は id:patorash が慣れないMySQLにも関わらずgeometry型でサクッと検索できるようにしてくれてスコアがかなり良くなり800点台に。そこからはうまくチューニングできずタイムアップとなりました。
思ったこと
- NginxもSQLも自分たちの知識でやることやったら、あとは何をやればよいのか正直わからなくなった。
- RubyはSinatraで来ることがわかっていたのであれば、Newrelicやログを取る仕組みを事前準備しておけばよかった。
- Rubyを選択したにも関わらずRubyのコード改善にほとんど取り組めていなかった。
ということで、来年はRubyできる人をもうひとり加えてリベンジしたい思いです。
チームについて考えよう!書籍「チーム・ジャーニー」の感想
前作「カイゼン・ジャーニー」は一人から改善を始め、やがてチームを動かしていくストーリー仕立ての快作だった。今度はすでに存在するチームをどう改善していくかがテーマ。今回も感情移入できるストーリーが素晴らしく、全編に渡って楽しく読むことができた。 本作はチームを改善していく前編と、チームをまたいだプロジェクトを改善していく後編に分かれている。
以下、箇条書きの部分は自分メモ。
前半
転職早々配属された部署でチームリーダーを言い渡される主人公、太秦(うずまさ)。チームとは名ばかりでそれぞれのメンバーが個人商店のように動いている。一癖も二癖もあるチームメンバーを前に太秦は「チームとは何か」を体験していく。
アジャイル開発のフレームワークありきではなくソフトウェアの開発の本質に迫ることが重要。
- 「アジャイル開発」自体がやりたいことではない。正しくソフトウェアを開発することの大切さ。
いきなりいろんなプラクティスを行ってもダメ。レベルに合った成長を促すことを勧めている。目標を階段状に並べた「ジャーニー」の設定。
- 成功体験を得ることでチームは成長する。そのために着実に小さい成功を積み重ねてチームに合った成功体験を得る必要がある。そのための「ジャーニー」という点が素晴らしいと思った。
共有ミッションに対してリードを設定する
- ドラッカー風エクササイズで見えてくるメンバーの特性から、その分野の方向性を決める「リード」を設定する。こうすることで何でも多数決で決定する、行き過ぎた民主主義から離れることができる。スピードは重要。
後半
「チームとは何か」について考え行動していくうちに太秦のチームにも一体感が出てきた。そんな中、会社の一大プロジェクトとして複数のプロダクトを一つの製品として統合する話が持ち上がる。チーム間のコミュニケーションすらうまく取れない状況から、どのような手法で製品にまとめ上げるのか。
チームを超える(越境)するがテーマ。
他チームとのやり取りはスプリントごとに輪番体制とする。
- これは運用が開始されたチームにも適用できる。バックログを倒しつつ、突発的な問い合わせ対応や障害対応に適応できそう。
みんなができることにこだわりすぎない。属人化することは個性が出ているということ。その人がいなくなってもなんとか対応できるプランBを目指すチームを作る。
- ここは「リード」を設定する考えと共通している。その分野に詳しい人の特性を活かす。
俯瞰と詳細。どっちかひとつだけではだめ。視座は高く視野は広ければよいというものではない。時には視座を落としてコードの隅々まで見る必要がある。重要なのは工程、広狭を自分たちの意思で行き来できるようになること。
- ベースとなる視座はマネージャーとプレイヤーでは異なって当然だが、時々行き来することで見えてくるものがあるというのは同感。
この本の素晴らしい点は、現実にありそうなシチュエーションを散りばめたストーリーだけにあらず、章末にチームのフォーメーションがどのように変化していったかを時系列で並べている点にある。章を重ねていくごとに主人公である太秦と一緒に「思えば遠くへ来たもんだ」と思わせる仕組みが面白い。
チームビルディングはなにか一つ改善を行えば終わりではなく、常に改善点を求めてチームの編成は移ろいゆくものだと感じた。 私のチームメンバーにも小さな成功体験を積み重ねて、より遠くへ共に歩んでいきたいと思う。
リモートワークで雑談について考えた
ちょっと前の話。
新型コロナウイルス対策ということで弊社でも急遽フルリモートの体制を整え、5月いっぱいは基本リモート勤務となった。私の家は2世帯住宅で妻は専業主婦、両親は元気なので隣の実家に子供を連れて移動してもらい、リビングでフルに働くことができた。両親と妻に感謝である。
さて、リモート勤務中はMicrosoftのTeamsの音声のみ常時接続し、必要なときのみミュートを解除してしゃべるというスタイルを取った。取った...と言っても実際はそれほど音声での会話は行われず、文字ベースでのチャットがメインだった。
私はマネージャーなのだがとにかく寂しかった。チームメンバーの活動はRedmineやGithubのコミットを通してよく動いていることは確認できる。しかし、自分のパフォーマンスは想像していた以上に出せている感じがしない。妻と子供に移動してもらって静かな環境なのにだ。5月は営業やSEの動きが縮退していのも理由の一つにあると思うのだが、なんとももやもやした気持ちのままリモート勤務を過ごした。
私は雑談が好きで、よく定時後には色んな話をするのだが、チームメンバーの若手の一人も雑談ができない点に不満を持っていた。 「リモート勤務は雑談できないのが不満。ってことは会社に雑談しに行ってるってことか。おれやべー奴じゃん!」とその若手はTeamsの分報に書き込んでいた。とっさに「わかる」と返事をしてしまった。私自身もヤベー奴だったのだろうか。
雑談ってなんだろう?「雑談は重要だぞ」と昔の上司から何度も言われていたし、自分自身も大切だと思っていた。
考えてみると、雑談を通してチームメンバーの性格、コンディションの把握や、興味を持っている技術や仕事に対しての考えを汲み取っていたのかもしれない。顔が見えない環境では、話のきっかけを掴むことができず雑談ができなかった。自分が思っていた以上にこの点にこだわっていたのだと気付かされた。
正直なところ、このあたりは月イチの1on1でも拾うことはできるんだけど、チームとして醸成していくためにはそこだけじゃだめなんだよなぁと考えてる。チームとしての阿吽の呼吸を作り出す雑談スタイルってなんだろう?
通常勤務に戻った今、オチは見いだせてない。
2019年のまとめ
はじめに
今回は仕事のお話です。バリバリ現場で働くことができるのは40代まで!なので40代は全力で駆け抜ける!と自分の中で宣言してからはや3年が経ちました。今年も自分なりに頑張ったと思います。会社の納会のあたりはヘロヘロだったからね。 というわけで、2019年最後のブログはマネージャーとして会社で何をやってきたのか振り返ってみようと思います。
自席でスマホが使えるようになった
うちの会社はよくあるセキュリティうんぬんの話で、開発者でありながら自席で自分のスマホを使うことができませんでした。カジュアルにアプリやWebサービスの話をするにしても廊下に出る必要があったのはとてもかっこ悪いなと思ってました。なので年のはじめから社内の会議で提案し、資料や制度を作ってなんとか権利を勝ち取ることに成功しました。 一度制度をきつく締め上げてしまうと、なかなか普通の状態に復帰させるのは難しいことがよく分かりました。 あと、いくら自分ひとりで頑張っても最後のひと押しをする人は必要で、その人を見極める能力って大事だなとも感じました。
会社で技術を磨くこと
会社で本を読んだり新しい技術を学習することについて、去年は「いいじゃんいいじゃん。やったれやったれ」と雑にOKを出していたんだけど、今年は一定の基準を設けることにしました。 それは「会社で働くということはつまりどういうことか?」という問いに自分の中で一定の結論に至ったからです。その結論とは「技術者は会社で自分の技術力を金に買えている」ということ。技術によりお客様の要望を叶え、その対価としてお金を頂いている。であれば、お金に変換できない技術は少なくとも会社では不要です。 ただ、将来を見据えて「こういう技術が必要なるからこういう理由で学習している」と言えるのであればウェルカムだし、みんなちゃんと言えるようになってほしいなと思ってます。
後輩への引き継ぎ
上に書いてる論理的に説明うんぬんと同じ話で、自分が携わった仕組みでなんでこういう仕組みになっているのかうまく説明できない業務がいくつかありました。そのせいで、うまく引き継ぎできずいつまでも私がズルズルと対応しているケースがあったので、まっとうにするべく努力しました。具体的に言うと
- サブで使っているさくらVPSのOSをCentOS6系から7系にアップデート。デプロイスクリプトをinit.dからsystemdに一新
- AmazonLinux2化を行いChefからAnsibleに構成管理ツールを移行(これはまだ途中だけど)
などが挙げられます。来年には一通りの業務はきれいな形にして引き継げそうです。
1on1
1年間続けてみたけど、合う人と合わない人がいるなとは感じてます。なので、自分の中でのベストプラクティスがまだ定まってない状態です。1on1をどういう場にするかは人によって微調整する必要があるのでこのあたりは2020年も探りながらベストを探っていく予定です。
アジャイル開発
新規開発の話が出てきたのでアジャイル開発に取り組むことにしました。お客さんありきの話ではなく自社サービスの話なのでプロダクトオーナーを社内に設定することができたのも採用理由としては大きいですし、他チームでアジャイル開発の経験があるメンバーがいるのも理由の一つです。 まだ2週間のスプリントを3回しか回してないので偉そうなことは言えませんが、スプリント計画会議はとても良いと思ってて手応えを感じてます。開発者はスプリント内での計画立案に責任を持つし、マネージャーはそれを達成させるために邪魔が入らないよう最大限協力する。このため、適度な緊張感が生じてチームが引き締まったと思います。 あとバーダウンチャートは残りのユーザーストーリをどれだけ実現できるか、つまり文字通り焼き尽くすことができるのかひと目で分かるのでとても良いですね。見ると気持ちがとても落ち着きます。
2020年は
チームの独立性を高めていきたいと思ってます。これは社内で孤立したいわけではなく「うちはこういうチームです」と言えるように個々のメンバーの力を見極めて最適化を進めていきたいという意味です。 あとは採用活動にも顔を出していきたいと考えてます。
最後になりましたが今年は id:Soudai さんをはじめ、社外の方々に色々相談に乗っていただき大変ありがたかったです。この場を借りてお礼申し上げます。